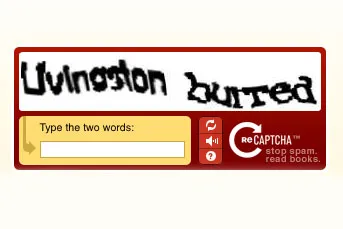

In an intriguing twist in Google's book digitising plans, the search giant has acquired reCAPTCHA.
The text scanning security system is best known for anti-spam systems that protect online forms from being repeatedly spammed. Computers can't easily read the squiggly images of the words, but people can.
But those forms are only one side of what reCAPTCHA does, noted founder Luis von Ahn and Google product manager Will Cathcart in a blog post, as the words in the CAPTCHAs are from old newspapers and books the firm has scanned.
The reCAPTCHA system scans images into plain text using Optical Character Recognition the very same system Google is using for its much-debated Google Books project while the security system not only prevents spam, but also helps tweak the scanning process.
"Computers find it hard to recognize these words because the ink and paper have degraded over time, but by typing them in as a CAPTCHA, crowds teach computers to read the scanned text," the post said.
Google has come under fire from publishers, authors and rival tech firms for its project to digitise the world's books, with some saying it will give the firm a copyright monopoly.
"Having the text version of documents is important because plain text can be searched, easily rendered on mobile devices and displayed to visually impaired users," the blog post continued.
"So we'll be applying the technology within Google not only to increase fraud and spam protection for Google products but also to improve our books and newspaper scanning process," it added.

-
 Cleo attack victim list grows as Hertz confirms customer data stolen
Cleo attack victim list grows as Hertz confirms customer data stolenNews Hertz has confirmed it suffered a data breach as a result of the Cleo zero-day vulnerability in late 2024, with the car rental giant warning that customer data was stolen.
-
 Lateral moves in tech: Why leaders should support employee mobility
Lateral moves in tech: Why leaders should support employee mobilityIn-depth Encouraging staff to switch roles can have long-term benefits for skills in the tech sector

